In Preliminary GPU Acceleration Data Indicates Significant Speedup of Hypothesis Update Operations, @collin demonstrated that Hypotheses update operations execute faster on a GPU ![]() .
.
How does this work fit into the overall Platform work?
One of the Monty’s Undesirable Effects is (115 Most experiment episodes take more than 1 second to execute). @collin’s data provided solid grounding for the intuitive idea that if Monty executes only on the CPU, and there are systems with GPUs, and HypothesesUpdater operations execute faster on GPU, then that contributes some magnitude to most experiment episodes taking more than 1 second to execute.

What we’d like to get to is the Desired Effect of (100 Most experiment episodes take less than 1 second to execute.) One way of improving the situation is to make an (Injection #1 When available, execute hypotheses update operations on a GPU), which will allow the hypotheses update operations to execute on CPU or GPU. Once hypotheses update operations can execute on CPU or GPU, and knowing that (102 Hypotheses update operations execute faster on a GPU) and knowing that (103 There are systems with GPUs), then that will contribute some magnitude to getting to most experiment episodes taking less than 1 second to execute.

@collin, here is what I’m thinking and a proposal for how we might go forward with this. Please note that I made this up overnight, so feel free to propose something different or point out where things don’t fit or don’t seem correct or true.
I’m conceptualizing everything into three main phases: 1) create a prototype, 2) validate the prototype, and 3) integrate the prototype. (This approach stems from RFC 14 Conducting Research While Building a Stable Platform).

I think the immediate and most accessible work will be 1) & 2) and that’s where we should focus our immediate effort. To this end, what I am proposing is that the prototype be created on a fork of tbp.monty so that we can get to validation as soon as possible. Here’s my initial impression of the work that needs to be done:
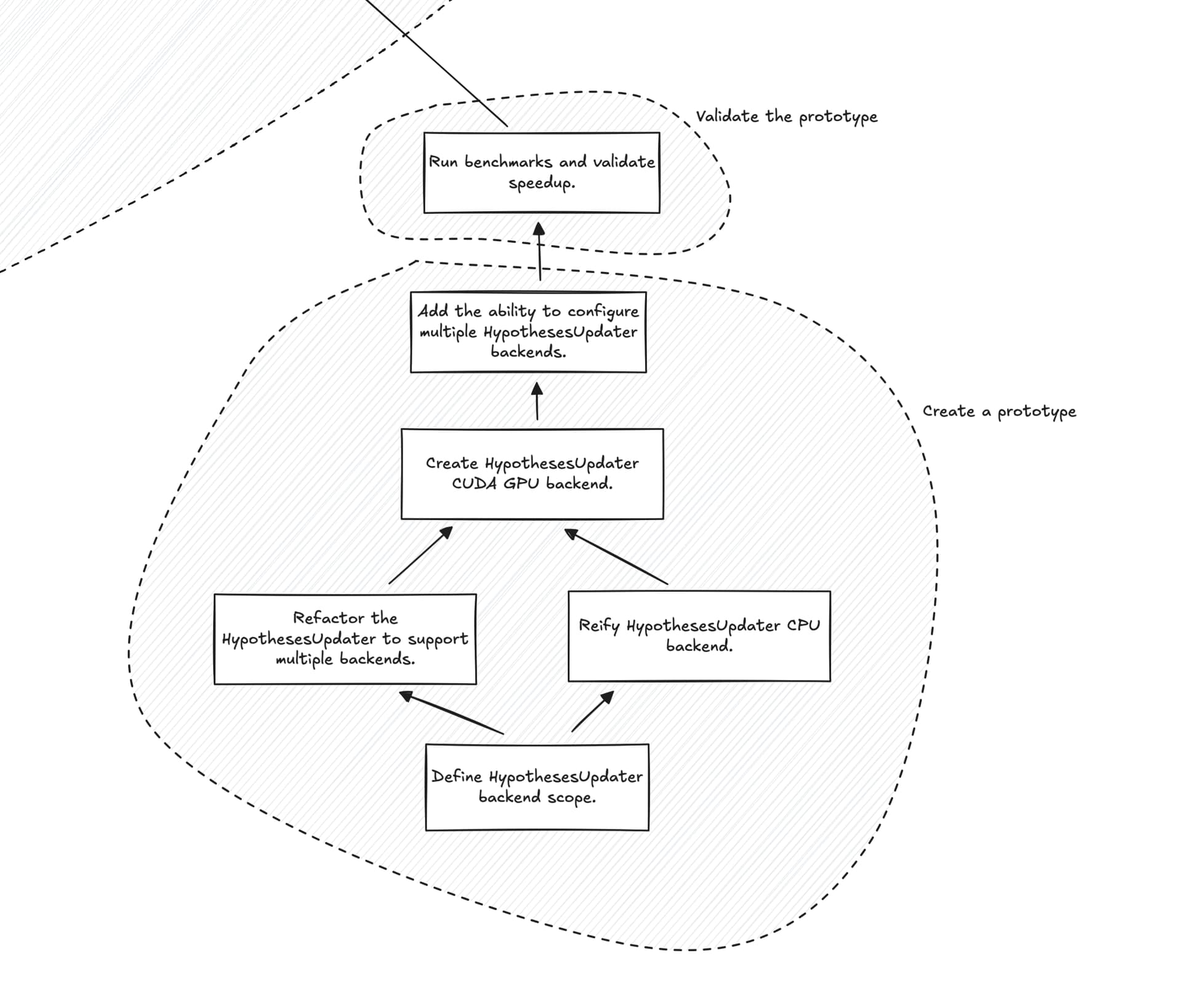
I think with this minimal work we’ll be able to run some benchmarks and evaluate the effect.
Now, you may have noticed a line going off of the top of the illustration. So, that’s leading to phase 3) integrate the prototype. For transparency, I want to share what I’m thinking we might want to do there:

As you can see, there’s a whole bunch more happening there. In summary, I think we’ll want the HypothesesUpdater CUDA GPU backend to be what I’m starting to call a “community component.” So, it wouldn’t be part of tbp.monty, but a separate package. The primary motivation is one of the “obstacles” (in the shape of stop signs/octagons), and that is our lack of in-house capacity for maintaining CUDA GPU kernels.
The primary reason why this might take a lot of effort is because yours would be the first community component, so on the TBP side we’ll need to figure out a bunch of things. If it helps, I’m thinking your part would only be the (Create a community HypothesesUpdater CUDA GPU backend) work, and the rest would largely fall upon TBP, with perhaps additional collaboration on a few of the details.
So, that’s the overview. Would love to hear your thoughts.
Cheers,
Tristan


