After 4 years in the works, we’re beyond thrilled to release TWO landmark papers. These are the most significant results yet from our work at the Thousand Brains Project, and the whole team is BUZZING.
Paper 1: Thousand-Brains Systems: Sensorimotor Intelligence for Rapid, Robust Learning & Inference
Meet Monty, our first working Thousand Brains System. It’s fast, robust, and outperforms Vision Transformers while learning online, from scratch, with no static datasets or retraining,no catastrophic forgetting, and eight orders of magnitude more efficient. Just like the neocortex intended.
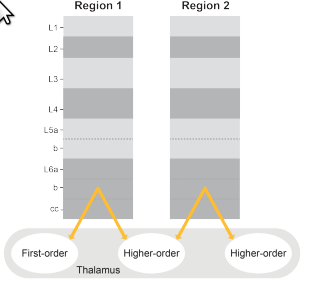
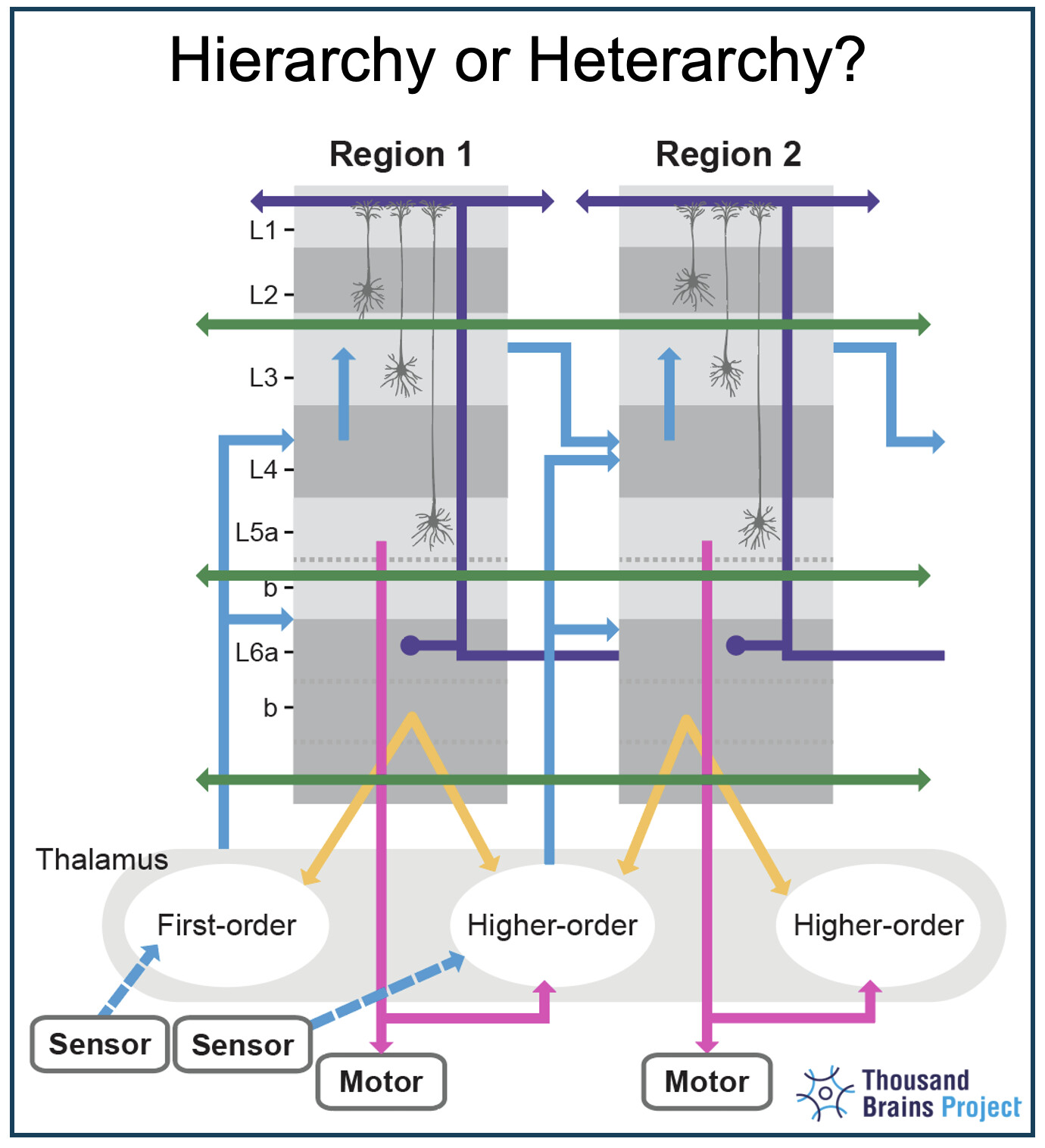
This paper dives into the often-ignored long-range, non-hierarchical connections in the neocortex. Why does the brain look like a mess of cross-talk, not a clean pyramid? Because that structure is the key to more powerful, flexible intelligence.
Interesting take for the L6b cortico-thalamic projections to higher-order thalamic nuclei in addition to L6a projection to lower-order thalamic nuclei. I did not know about those connections described in your Hoerder-Suabedissen et al., 2018 reference. Still, we have to take into account that there are around 10 times less L6b neurons than L6a neurons. The same research group also has an interesting interpretation of those L6b projections in this paper.
Yes, non-hierarchical connections that travel through the white matter function the same as those that go directly column to column. The general view, that we adopt, is that the white matter is a more efficient wiring method. If an axon has to go long distances, it is shorter to go into the white matter and head more directly to its destination. If an axon only has to go a few columns over, it is shorter to go straight there.
Thank you Jeff for the clarification. Indeed your theory does make sense. That said, I currently hold a different view, which I’ve outlined in this post:
Degree of specialization of each cortical column: If we view the cortex as a multi-agent system where each agent possesses its own knowledge, the degree of knowledge overlap between agents becomes a fundamental parameter. This can be visualized as a continuum with two extremes: on one end, each agent is the sole expert in its domain; on the other, each agent models the entirety of the system’s knowledge. Where should we place the cursor on this spectrum? The locality of lateral coupling between cortical columns in superficial layers suggests a “local” voting process, where a cortical column collaborates primarily with only a few dozen neighboring columns. In contrast, from my understanding, the TBP leans further toward the other end of the continuum, as it implies that even a cortical column from V1 could recognize and contribute to identifying complex objects, such as a cup.
I’ll give it more thought, especially in light of Artem Kirsanov’s new video, which helped me better conceptualize the key points where our views differ.
@mthiboust Good question, I would say the TBT also falls somewhere in the middle on this spectrum. The mug example is illustrative, and can maybe give the impression that we think all columns learn mugs, down to V1 etc., but that’s not really the case. We describe this more here in our FAQ. To highlight a particular section:
Blockquote
One important prediction of the Thousand Brains Theory is that the intricate columnar structure found throughout brain regions, including primary sensory areas like V1 (early visual cortex), supports computations much more complex than extracting simple features for recognizing objects.
…
Blockquote
We use a coffee mug as an illustrative example, because a single patch of skin on a single finger can support recognizing such an object by moving over it. With all this said however, we don’t know exactly what the nature of the “whole objects” in the L2/L3 layers of V1 would be (or other primary sensory areas for that matter). As the above model describes, we believe they would be significantly more complex than a simple edge or Gabor filter, corresponding to [2D or] 3D, statistically repeating structures in the world that are cohesive in their representation over time.
It is also important to note that compositionality and hierarchy are still very important even if columns model whole objects. For example, a car can be made up of wheels, doors, seats, etc., which are distinct objects. The key argument is that a single column can do a surprising amount, more than what would be predicted by artificial neural network (ANN) style architectures, modeling much larger objects than their receptive fields would indicate.
Thank you @DanML ! We are in the process of submitting them to a journal, we’ll let you know when they are published. We are also looking at some conferences and other venues to present the work, although the papers are too long for typical ML conferences. On that note, if anyone is organizing a conference and looking for a speaker, please feel free to let us know.
Do you have a rough idea of the order of magnitude for the number of categories you expect a single LM / cortical column to learn and recognize?
Related question about computational efficiency: I’m curious how Monty scales with the number of categories. What would happen if we increase the 77 categories in the YCB dataset by a factor of 10 — or even scale up to the 21,000 categories used in ViT?
If I had to guess, it would be 10-100 (i.e. dozens, similar to the scale of the YCB dataset, or smaller). If you’re interested in the question from a biological perspective, I would recommend checking out the analysis in Lewis et al, 2019 on the representational capacity of grid-cell modules for unique object location representations. While it is parameter specific, they start seeing degradations in performance when trying to represent e.g. more than 70 objects (Figure 7a).
In terms of Monty, we currently expand memory for objects arbitrarily. We discuss this in the paper in section 4.3.3, i.e. that the inference FLOPs therefore scales linearly with the number of objects learned. As we discuss there, this would be mitigated by future learning rules that merge existing models over time, as well as hierarchically decomposing objects to enable greater model re-use.
In the longer term when we actually want to optimize Monty’s performance, it might make sense to shift to a system with a fixed capacity that gradually degrades when capacity is reached, similar to the grid cells modules in Lewis et al. This would result in a fixed FLOP cost as a function of models known. Ultimately the highly parallelizable nature of columns could inform other hardware optimizations, like memory that is local to each learning module. This seems likely to be what the brain is doing, so we’re not worried too much about it at the moment.
Oh nice, thanks for the rough estimate. I had initially assumed you were thinking of a much higher number. Given that, it makes sense that the “cup” object isn’t part of the limited pool of 10–100 objects a V1 column can learn and recognize.
I’ve got more questions and comments, but I’ll hold off so we don’t go too much off topic.
Nice, sounds good! And yeah for what it’s worth, some V1 columns might learn an object like a mug. Voting does not require that all columns know the same objects, only that there is some overlap between objects known by different columns. Any given column might have a unique set of objects that it knows (mug, hat, bowl) vs. another column (ball, mug, pen). In this case, they can still vote on whether they are both observing a mug. Another, third column (pen, hat, ball) would not participate in the voting if evidence for all of its objects is low, and would never vote on the presence of a mug.
 Paper 1: Thousand-Brains Systems: Sensorimotor Intelligence for Rapid, Robust Learning & Inference
Paper 1: Thousand-Brains Systems: Sensorimotor Intelligence for Rapid, Robust Learning & Inference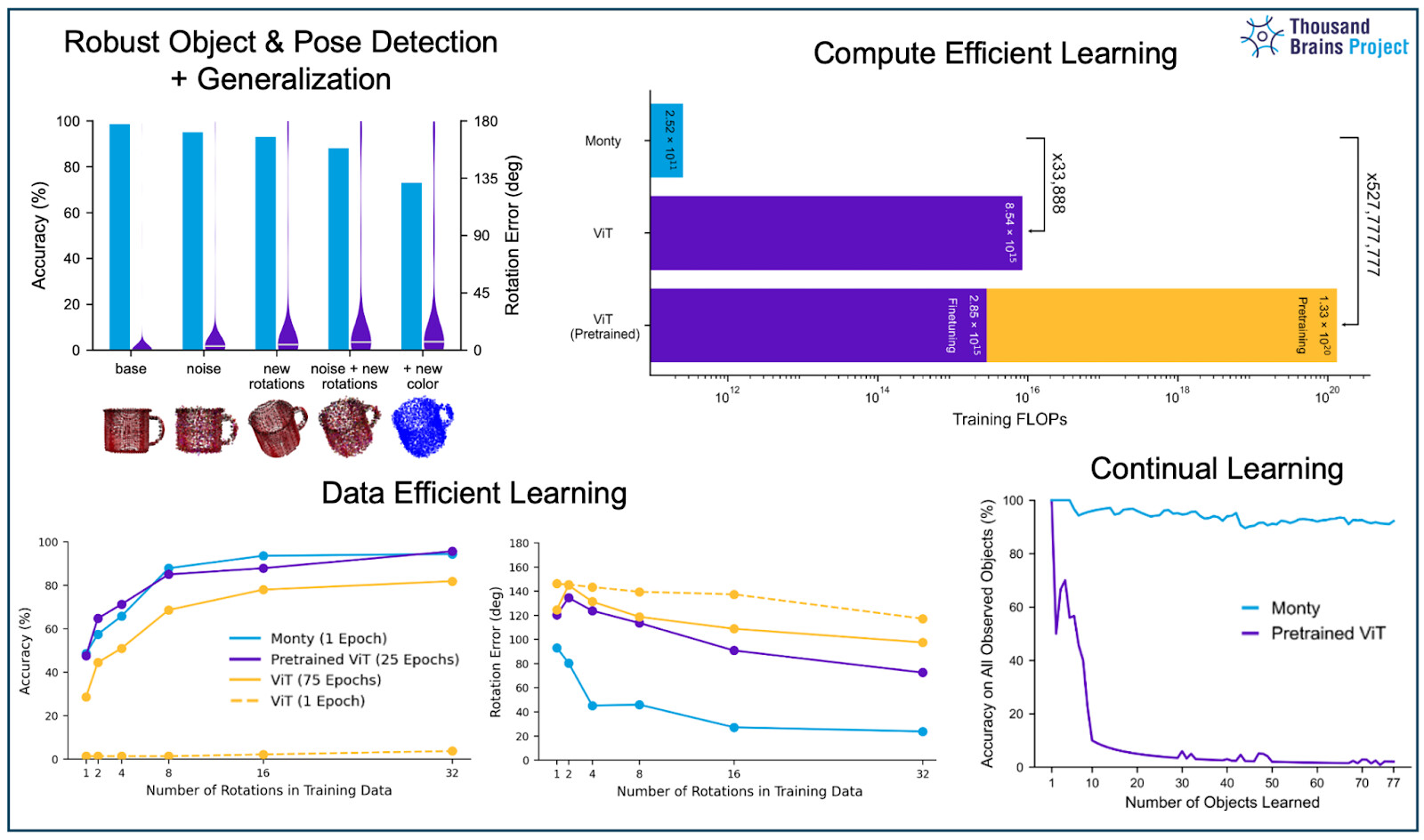
 Watch @nleadholm break it down:
Watch @nleadholm break it down:

 Coming soon:
Coming soon: Plain-language explainers
Plain-language explainers Q&A sessions with the researchers
Q&A sessions with the researchers