Working on exploiting audio waveforms or spectrograms, I am thinking of trying Monty approach for audio processing. My blocking point is the definition of reference frame for audio (as it is a temporal and not spatial signal). I struggle to understand how to give the reference frame information. My first thought were to give it points were salient freq. or magnitude occur but I am not very comfy. Any thughts ?
Hi @_sgrand
We are working on modeling sequences (here is a recent object behavior research meeting video). For now, the only way we could think of is define a 1D reference frame where time is the only dimension and it can just be traversed in one direction. But we I think the object behavior mechanism will be much better. Watch this space!
1 Like
Here are some random thoughts on the topic; no extra charge…
-
Timing (e.g., impulse, phase) information for an event can be used to determine the location of the sound’s origin. For example (AIUI), normal human hearing can pinpoint the location of a coin striking a window within about a foot at a distance of 30’.
-
The head’s position can be changed (e.g., tilted, turned) to test hypotheses about a sound’s location. Some animals (e.g., cats, horses, some dogs) can also swivel their ears to localize sounds.
-
The sensing nerve cells in the cochlea are spread out in a manner similar to touch sensors on a fingertip. I wonder whether and how the low-level sensory processing might take advantage of this.
-
As a whole, the ear operates a bit like a (somewhat) directional microphone, feeding a spectral analysis subsystem. That is, the brain does not receive sounds simply as changing amplitude over time.
1 Like
Hi
Yes, I think the ear contains lots of little hairs of different lengths which resonate at different frequencies. Each hair stimulates a nerve cell. In this way the ear converts time domain audio into frequency domain. We can emulate that in conventional software using a Fourier transform.
So you can transform the time domain signal into a sequence of frequency domain frames. The frame rate will be determined by the audio sample rate and the length of transform you use.
Again brains manage to do that clever thing of being able to recognise a melody independent of pitch and speed..
As Rich says, direction finding can be done by cross correlation of the time domain data. The brain has the advantage of a continuous instantaneous frequency conversion, a sequential digital computer cannot do that, it has to wait to collect a whole bunch of samples and then do the maths. Streaming transforms can be implemented but it’s still only one sample in one bin out.
1 Like
I’ve been thinking about this topic myself, especially after seeing the remarkable I Saved a PNG Image To A Bird video.
A peculiar idea occurred to me; what if frequency, power, and time were to be mapped to the XYZ axes?
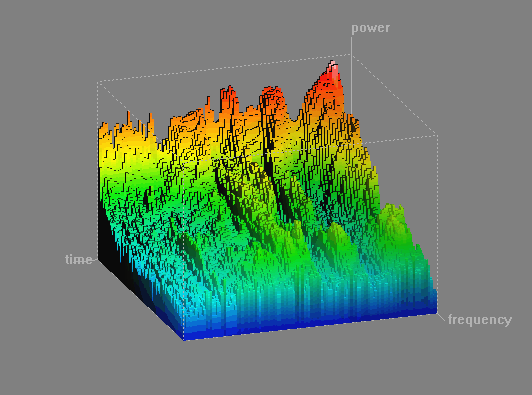
This way, songs could be interpreted as 3D objects, and an audio-oriented learning module could potentially directly leverage Monty’s existing capabilities for learning and inference. I guess this would be a bit crude, but still an interesting starting point, to say the least. A kind of “Monty-flavored Shazam” ![]()
This brings a side-topic: how does Shazam work? Well, there’s a pretty good article on the subject. Long story short, when a publisher uploads a new song, a FFT spectrogram is computed on a sliding time window, and as the song progresses, the maxima of the spectrogram are continuously identified. Those form a kind of “constellation”, which is fingerprinted at regular intervals with a hash function, and stored in a database. Then, when a user starts the app, it does the same thing, but for a shorter duration, which might only identify a few of the song’s thousands of fingerprints, then look them up in the database.
Now, hashing doesn’t make sense within Monty, because it’s not how the brain works. However, it might provide an answer as for the reference frame; Shazam relies on maxima specifically for their resistance against background noise, on top of uniqueness and low-cost hashing.
So yeah, I’m considering a proof-of-concept learning module of the sort, at least to begin digging my fingers in the code, if anything. I don’t think it would scale particularly well in terms of data quantity over time, and it doesn’t address the brain’s broader auditive concepts like phonemes, musical notes, repetition and pattern detection, invariance to speed/pitch/distortion, etc. but it would be a start.
One might ask “but what about spatial location?” Well, our auricle is a special geometrical construct which acts as a frequency modulator (head-related transfer function), and the brain learns / knows how to map those modulations to directions. It has been done in robots but it’s a bit cumbersome in my opinion. Multi-mic triangulation or an array of directional mics are probably more effective at this kinda job (lots more info here: 3D sound localization - Wikipedia), at which point it becomes a typical sensor fusion challenge that can be resolved by traditional methods. The approach to choose comes down to whether you prioritize form or function of the robot.
6 Likes
@AgentRev that video is pretty rad. I’m a Benn Jordan fan.
Thinking about frequency and spectral power as dimensions, along with time, is I think the right idea. But where I personally would start is with speed/pitch invariance (as you suggested). More specifically, I think reference frames are a very natural way to think about how we are able to recognize a melody regardless of what key it is played in, how fast it’s being played, and which instrument is playing it. To my mind, this ability requires intelligence in a way that Shazam’s old hashing method doesn’t.
What I’d try to tackle first is key invariance. There are 12 keys, and they are cyclical. I can take a melody in the key of C and shift it up a whole step and play it in C#/Db. I can shift it up again and play it in E. But eventually I run out of keys and I’m back to C. This is such a nice parallel to spatial rotations. The 12 keys are just like 360/12 = 30 degree rotations. Recognizing a melody would then reduce to “object” and “pose” recognition, where the pose would effectively be the key a melody was played in, and the object is the learned melody.
I’m leaving out a lot of details, but that’s the direction I’d find most fun, and it’s a really natural fit for Monty.
3 Likes
@sknudstrup Great ideas, love the feedback. Although, that’s tiny bit much to accomplish all at once ![]() My initial goal is more along the lines of voice recognition than melody identification. I guess I was slightly but unintentionally misleading in that regard, with my mentions of Shazam and notes. I’d wanna start with short MIDI samples to see if Monty can learn and infer them, without any bells and whistles.
My initial goal is more along the lines of voice recognition than melody identification. I guess I was slightly but unintentionally misleading in that regard, with my mentions of Shazam and notes. I’d wanna start with short MIDI samples to see if Monty can learn and infer them, without any bells and whistles.
This would provide Monty with a baseline audio capability, thus enabling the eventual association of sounds with objects during training, e.g. Monty hears “mug” while mapping a coffee mug, and remembers. Then, suppose you have some type of Monty-meets-World experiment with a motorized camera, and then say “mug”, it could recognize the sound and look at the mug if it’s in its peripheral vision. I think it will get very interesting from that point on… ![]()
I would qualify myself as a purist when it comes to biological plausibility, prefering to focus on the minimal substrate. Since the 12-key system is mainly a cultural construct and not strictly biologically rooted, I don’t think I’d tackle that part. However, I certainly agree that pitch invariance is necessary, since it’s biologically rooted. In that regard, I’d probably work with octaves (in the form of binary logarithms) and frequency ratios. If somebody would want to add a 12-key “layer” on top of that for musical applications, then they’d have a decent portion of the groundwork covered!
3 Likes