Hi Viviane!
Thanks so much for such a detailed and comprehensive answer. This kind of communication is extremely helpful in understanding Monty, its future direction, and the possibility of contributing to it. Let me respond inline:
we still have open questions on the theory side (including how to model object distortions,
Could you clarify whether to model object distortions is conceptually different from to identify objects that have been distorted?
…if you want to start building an application today, you will have to limit it to tasks that don’t require those capabilities or help contribute to the code base (which would also be awesome!).
I believe that if I manage to launch this project, it will already be a kind of contribution to the promotion of Monty. As we all know, even the most brilliant idea needs evidence of its applicability. Monty is certainly one of those ideas; perhaps even one of the most brilliant ideas that has ever been conceived in the history of human invention! This means that a demo implementing the strategic advantage that TBP offers will be very important for public and the AI community to quickly understand where to focus their attention and efforts. Of course, if I have a chance to contribute beyond my project, I’d be happy to do so (I may have already done so in hindsight, but as far as I can tell, the problem I was working on is not on your immediate agenda yet).
I’m sorry to say that we currently don’t have a finalized plan on how Monty will model object distortions (or how the brain does it), but we have been talking about it a lot in our latest research meetings, so hopefully we will come up with a good solution soon.
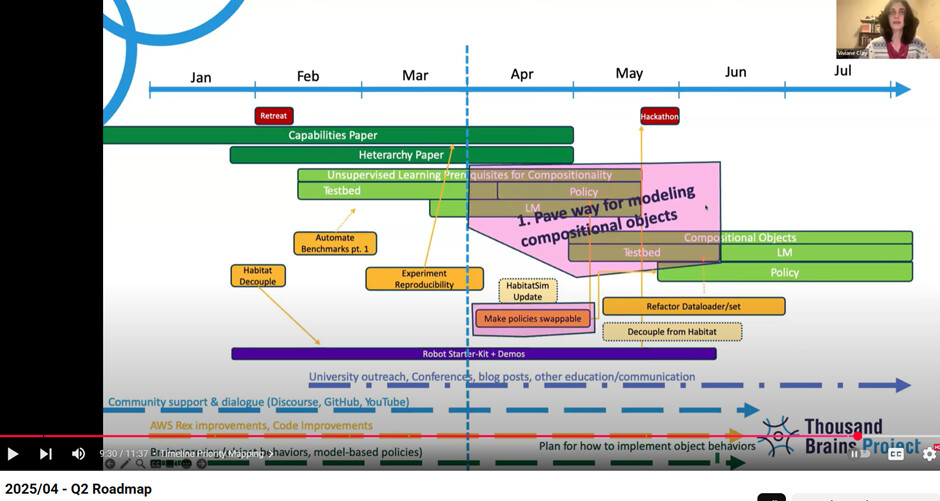
The “compositional objects” milestone on our research roadmap is not meant to include modeling object distortions. However, given our theory of how hierarchy works in the neocortex, we think that learning compositional objects will already cover a lot of cases of distorted objects (potentially all, but we need to test this). I’m not sure how interested you are in this, but in a nutshell, the idea is that the parent object will store the orientation and scale of the child object on a location-by-location basis. If there is a logo on a cup, we don’t just store one location of where the logo is on the cup. The logo-cup model in the parent column will store the logo feature and its pose at many locations. The logo could bend in the middle, and we would just store a different location and orientation for the logo on the parent model for those parts of the logo.
This is extremely interesting to me, so let me ask you a question right away. Perhaps I have misunderstood the context in which you use the term “hierarchy” or “object” or “to model object distortions” (though I have of course read everything about Monty’s approach). I have a couple of purely intuitive suggestions, based on everyday experience and addressing the above definition of “to identify objects that have been distorted”. The first suggests to me that the key to implementing the function is a mechanism for “computing” the topology of the object. If it is intact, then we recognize this object when it is distorted (how exactly remains an open question). Jeff mentions Dali’s painting in his book as an illustrative example.
The second suggestion is that we can recognize such a distorted object regardless of whether it is contained in another object or whether we see it each time, so to speak, in a vacuum.
In a few months, we will hopefully have a better idea of how well our hierarchy solution works for all kinds of object distortions and whether we need another mechanism (related to object behaviors that distort an object).
Solving the “distorted objects” problem will definitely be a major milestone in Monty’s development. Because it will prove that it opens the way to implementing real intelligence, something that, to my knowledge, no one has come close to yet. I have no doubt that you can handle it.
In regard to the compositional models milestone, we will likely need at least until the end of Q3 to have a fully tested and integrated version of what we plan to add to Monty for this. The DMC paper you have heard so much about has taken more of our time than anticipated (but it was well worth it, as you will hopefully see soon!).
I can’t wait! 
If you can give some more details on your intended application, I could also maybe give you my thoughts on whether you could solve it without a hierarchy.
Yes, I would really appreciate your expert opinion on how feasible it is. And your guess on how long it might take to implement such a project would be invaluable. You can see the presentation [here](OneDrive d=cc02a7a1-c0a5-d000-07c8-1c1082d8fd8e&originalPath=aHR0cHM6Ly8xZHJ2Lm1zL3AvYy8zOTY2NGQ0ODYwNjg3YWMyL0VULWp0Und1YmVWSG1tSTdhRlRDTTE4QlFLSlM1QTRBVktseWpDUW4zcExWcGc_cnRpbWU9ZEhPZDFyMm8zVWc&CID=1f23adec-e842-4a71-bdb9-6faeb4e18afc&_SRM=0%3AG%3A53&file=HALS%20presentation.pptx).
I hope this helps!
It really does and I appreciate it much! 
SY Srgg