Hello,
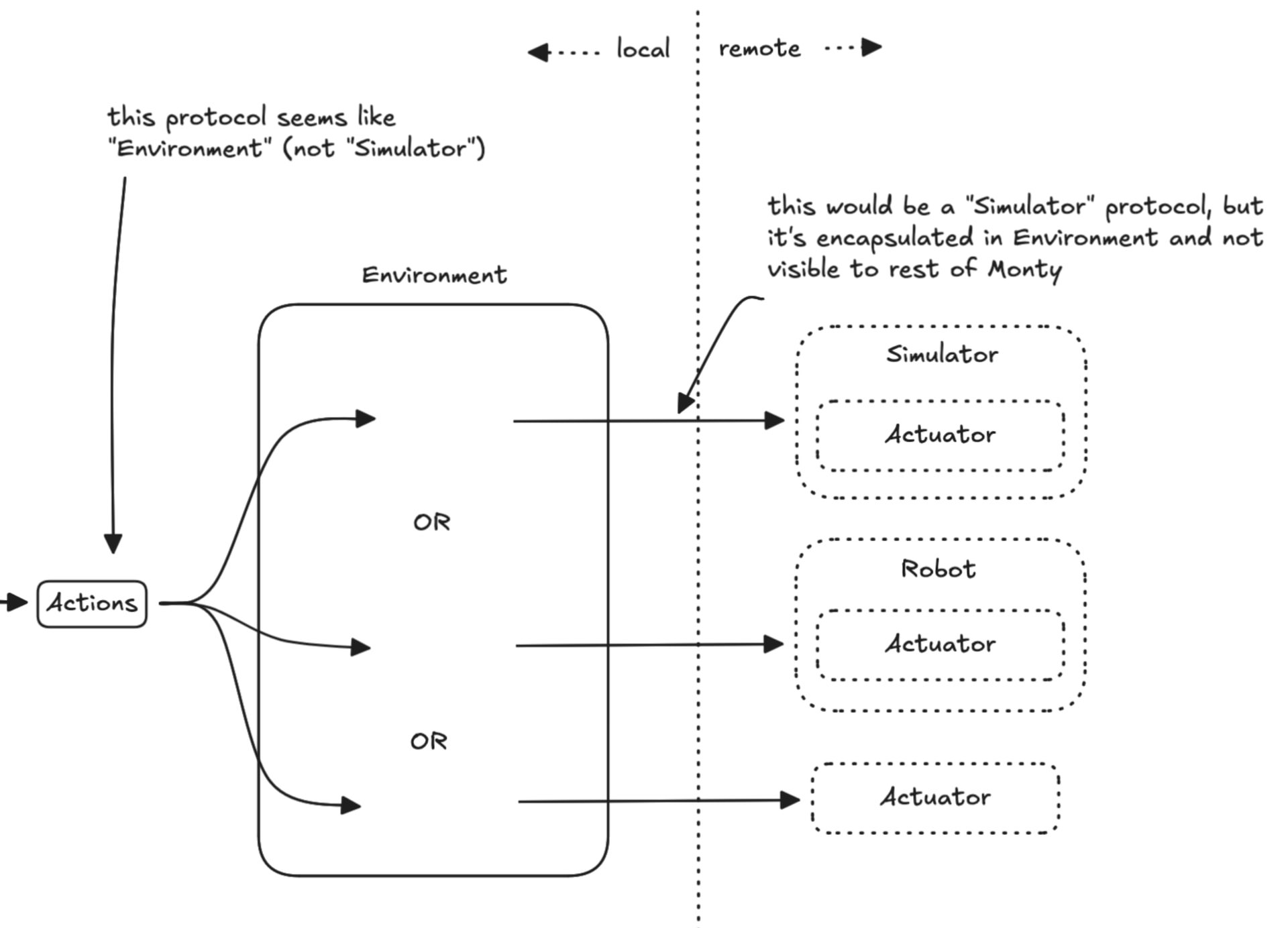
In my spare time have been working on a version of monty that talks to habitat in a different process via IPC, inspired by the grpc prototype done by the team last year. The branch now passes all the tests. What I have done with this is validate the basic data exchange protocol between monty and the simulator, without grpc (which I considered to be a sub-optimal transport), which can now be further worked on to use different transport protocols or even different serialization formats (currently protobuf→ maybe cap’n’proto ?). The most basic transport in place right now is based on multiprocessing.queues. Tests take %50 longer with this approach (I haven’t run any experiment with it yet).
This was something I did somewhat to prove myself I could do it, simultaneously a fertile ground to explore some low-level ideas, and function as a nice induction to a project I always admired. Eventually it could become a PR, but in time it got a life of its own due to some side-quests. This said, I have been silently adjusting the code to the larger architectural direction the system takes, but in its current state there are architectural questions arising, for which I think I may have a privileged view due to how far I took it, and that’s why I’m sharing one of them here, asking for insights.
The main open question for me going forward relates with configuration. In my version, habitat has a client and a server modules. The server encapsulates the code to be externalized, eventually to a diff repo, eventually using a different python version. I had to change most of the class names in the hydra config related with environment initialization, to point to the server module, but this works only as long as that module exists in the monty repo. Externalizing those classes (and eventually locking them in a distinct python version) will break the experiment initialization. My question to the team is therefore about what are your plans for this topic, please ?
Thank you ![]()
Nuno