Hey there Avinash,
Its been a little bit since you asked this, so I figured I’d step in and take a crack and answering your question.
To start, I think we should ask ourselves, what is a ‘pose’. To me, pose is context. Applied spatially, a pose may be viewed as a sensors position and orentation, relative to the enviroment.
However, applied abstractly, a pose might be a paragraph in a book, a mathematical state within a given problem, or perhaps a set of assumptions within a political model.
We had actually had a discussion on this very thing some time back. It was on how to apply sensorimotor learning against network topology. You can check it out here: Extending and Generalizing TBT Learning Models
To answer the second part of your question (how Monty learns a paragraph of a book), we’d actually want to understand how nodes and edges get applied to abstract representations.
A node might come to represent concepts and symbols (e.g., words/characters, mathematical symbols or logical propositions).
Edges then become the relationships found between those concepts and symbols. (syntax rules, cause-effect chains, et cetera.)
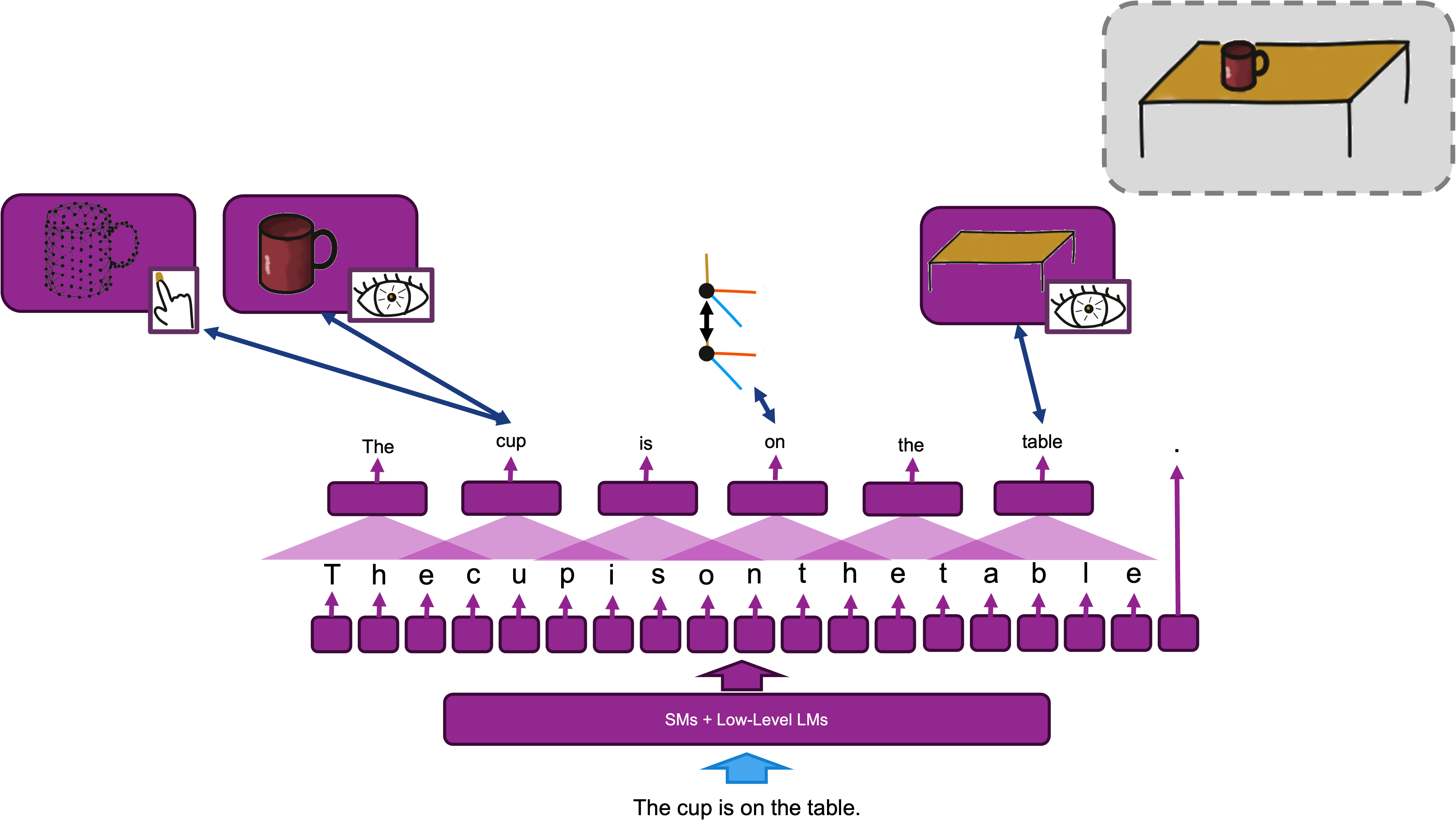
So now, with all this in mind, how does Monty come to learn a paragraph?
Imagine giving Monty a paragraph. It would:
(1) Break the text into tokens (e.g., words or concepts).
(2) Identify relationships between those token (subject-verb-object triples, co-reference, topic flow, etc).
(3) Form a graph of these concepts — similar to how it models features-at-locations.
Over time, Monty would learn to associate meanings based on recurring patterns of relationship, then use its evidence-based updates to reinforce hypotheses about what concepts (aka poses) mean in relation to their surrounding “enviroments.” Its actually not terribly differrent from how Transformers work, albiet Monty gets there in a more sensorially grounded way.
I feel like I’m beginning to get into the weeds here a bit. Does all this make sense?