I’ve been thinking about this topic myself, especially after seeing the remarkable I Saved a PNG Image To A Bird video.
A peculiar idea occurred to me; what if frequency, power, and time were to be mapped to the XYZ axes?
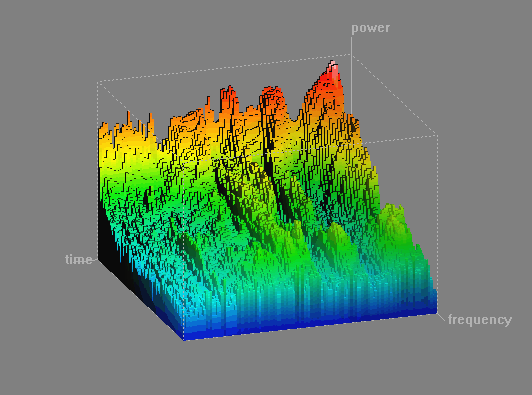
This way, songs could be interpreted as 3D objects, and an audio-oriented learning module could potentially directly leverage Monty’s existing capabilities for learning and inference. I guess this would be a bit crude, but still an interesting starting point, to say the least. A kind of “Monty-flavored Shazam” ![]()
This brings a side-topic: how does Shazam work? Well, there’s a pretty good article on the subject. Long story short, when a publisher uploads a new song, a FFT spectrogram is computed on a sliding time window, and as the song progresses, the maxima of the spectrogram are continuously identified. Those form a kind of “constellation”, which is fingerprinted at regular intervals with a hash function, and stored in a database. Then, when a user starts the app, it does the same thing, but for a shorter duration, which might only identify a few of the song’s thousands of fingerprints, then look them up in the database.
Now, hashing doesn’t make sense within Monty, because it’s not how the brain works. However, it might provide an answer as for the reference frame; Shazam relies on maxima specifically for their resistance against background noise, on top of uniqueness and low-cost hashing.
So yeah, I’m considering a proof-of-concept learning module of the sort, at least to begin digging my fingers in the code, if anything. I don’t think it would scale particularly well in terms of data quantity over time, and it doesn’t address the brain’s broader auditive concepts like phonemes, musical notes, repetition and pattern detection, invariance to speed/pitch/distortion, etc. but it would be a start.
One might ask “but what about spatial location?” Well, our auricle is a special geometrical construct which acts as a frequency modulator (head-related transfer function), and the brain learns / knows how to map those modulations to directions. It has been done in robots but it’s a bit cumbersome in my opinion. Multi-mic triangulation or an array of directional mics are probably more effective at this kinda job (lots more info here: 3D sound localization - Wikipedia), at which point it becomes a typical sensor fusion challenge that can be resolved by traditional methods. The approach to choose comes down to whether you prioritize form or function of the robot.